براي من كه زياد پيش آمده است
براي ديگران نميدانم
بارها شده در سايتها
يا نرمافزارهاي تحت وب
دنبال مقاله يا مطلبي ميگردي
صدها صفحه مطلب ذخيره ميكني
اما هزاران تگ و فرمت و تصوير
پيرامون متن مورد نظرت را گرفته است
چه بايد كرد؟!
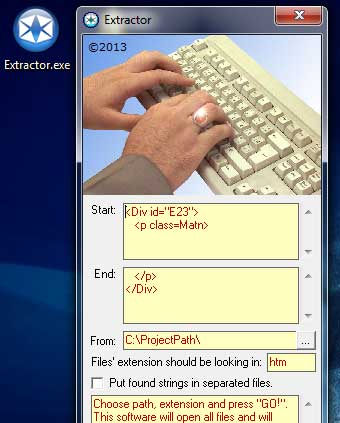
معمولاً چند خط كد مينوشتم
اول و آخر مطلبي را كه ميخواستم برميگزيدم
فرمتي كه منحصر به فرد باشد
و تكراري
باقي كار را نرمافزار انجام ميداد
بسيار ساده و سريع
تمام فايلها را ميگشود
دنبال فرمتهاي داده شده ميگشت
آنها را كه مييافت
درونشان هر چه مطلب بود بيرون ميكشيد و جداگانه ذخيره ميكرد
شايد هزاران صفحه مطلب را با اين روش تا به حال استخراج كردهام
هر بار به يك دليلي
و به يك نيازي
اما اينبار...
با خود گفتم چرا يك ابزار كوچك و ساده نباشد
اين كار را براي هميشه به انجام رساند
چرا مجبور باشم براي هر كنكاشي
يك بار كد بنويسم؟!
اين شد كه نوشتم
نرمافزاري كه در اين نشاني قرار دارد (http://movashah.id.ir/o/Extractor.zip)
فرمت اول را ميدهيد
فرمت آخر مطلب را هم
نشاني شاخهاي كه فايلها در آن قرار دارند
پسوند فايلهاي مورد نظر
تا از ساير فايلها صرفنظر نمايد
اگر مايل بوديد صفحات مختلف به هم نچسبند
گزينه مربوطه را تيك بزنيد و فعال كنيد
كه فايلهاي متعدد ساخته شود
در آخر هم...
سايتهايي كه مقالات و اخبار ارائه مينمايند
مهمترين هدف براي استفاده شخصي از اين ابزار هستند
حتي وبلاگها و خصوصاً آرشيوهاي وبلاگ
براي كاربردهاي مفيد البته.
توضيح1: اگر سيستم عامل شما امكان اجراي آن را نداشت
فايل msvbvm60.dll را دانلود كنيد و در كنار برنامه اجرايي قرار دهيد
و يا بسته كمكي vbrun60sp6.exe را دانلود و نصب فرماييد.
توضيح2: اين نرمافزار به صورت خودكار با باز كردن نخستين فايل
كاراكترست آن را شناسايي كرده (utf-8 يا ascii يا unicode)
و فايل خروجي را متناسب با همان ميسازد.
 ...: اسم اين آيكون هاي كوچكي كه وقتي سايت پدر مادر داري را باز ميكنيم گوشهء اسمش در تب مرور گر مياد چيه؟
...: اسم اين آيكون هاي كوچكي كه وقتي سايت پدر مادر داري را باز ميكنيم گوشهء اسمش در تب مرور گر مياد چيه؟





